Ensemble Models: How to Make Better Predictions by Combining Multiple Models with Python Codes (Explained)
Have you ever wondered how Netflix recommends movies that you might like? Or how Amazon suggests products that you might want to buy? Or how Google ranks web pages that match your search query?
These are all examples of machine learning, a branch of artificial intelligence that enables computers to learn from data and make predictions or decisions. Machine learning is everywhere nowadays, and it powers many applications that we use daily.
But how do machine learning models work? And how can we make them more accurate and reliable?

One way to answer these questions is to look at ensemble models, a technique that uses multiple models to make better predictions than any single model alone. Ensemble models are widely used in machine learning and data science, especially for tasks like classification and regression.
I’m gonna let you in on a little secret. I’ll be spilling the beans on some of the most common types of ensemble models and how they really tick. And to top it off, I’ll be showing you how to whip up your own ensemble models with Python and Scikit-learn. Believe me, you’ll be slaying real-world problems with your newfound skills by the end of this article!
What are Ensemble Models?
The idea behind ensemble models is simple: instead of relying on one model, why not use multiple models and combine their predictions? This way, we can leverage the diversity and complementarity of different models and get a more robust and accurate forecast.

For example, suppose we want to predict whether a customer will buy a product based on their age, gender, income, and browsing history. We could use a single model, such as a logistic regression or a decision tree, but it might only capture some of the nuances and patterns in the data. Alternatively, we could use multiple models, such as logistic regression, a decision tree, a k-nearest neighbour, and a support vector machine, and combine their predictions using some rule or algorithm. This is an example of an ensemble model.
There are different ways to create and combine multiple models. Depending on how they do it, we can classify ensemble models into five main types:
- Majority
2. Average
3. Stacking
4. Bagging
5. Boosting
Let’s see what each type means and how it works.
P.S. — Just wanted to give you a heads-up that I’ll be using the default parameters for the algorithms we’re working with. Of course, if you want to dive into hyperparameter tuning, feel free to give it a go!
MAJORITY

A special case of bagging is when the models are used for classification instead of regression. For example, if you have three models that predict whether it will rain in Paris as yes or no, you can take their majority vote and get yes as the final prediction. This is also called a majority ensemble or a plurality ensemble.
The advantage of majority voting is that it reduces the error rate of the predictions, meaning that they are more likely to be correct. The disadvantage is that it does not account for the confidence or probability of each prediction, meaning that it can ignore some useful information.
To implement a majority ensemble in Python using scikit-learn, we can use the VotingClassifier class with the voting parameter set to ‘hard’. This class allows us to specify a list of models and a voting method (such as ‘hard’ or ‘soft’) to combine their predictions.
Here is an example of how to use a majority ensemble for classification:
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Generate a random dataset for classification
X, y = make_classification(n_samples=1000, random_state=42)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define three different models
model1 = LogisticRegression(random_state=42)
model2 = DecisionTreeClassifier(random_state=42)
model3 = SVC(random_state=42, probability=True)
# Combine the models using majority voting
ensemble = VotingClassifier(estimators=[('lr', model1), ('dt', model2), ('svc', model3)], voting='hard')
# Fit the ensemble on the training data
ensemble.fit(X_train, y_train)
# Evaluate the performance of the ensemble on the testing data
print(f"Accuracy of the ensemble: {ensemble.score(X_test, y_test)*100} %")Output:
Accuracy of the ensemble: 85.5%AVERAGE
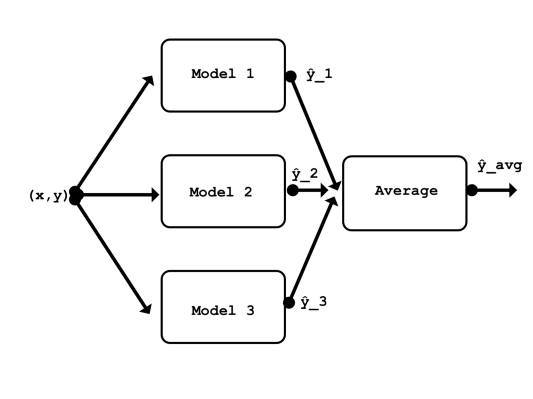
The simplest way to combine multiple models is to take their average. For example, if you have three models that predict the temperature in Paris as 15°C, 18°C, and 20°C, you can take their average and get 17.67°C as the final prediction. This is also called a mean ensemble.
The advantage of averaging is that it reduces the variance of the predictions, meaning that they are less likely to be far from the true value. The disadvantage is that it also reduces the bias of the predictions, meaning that they are less likely to be close to the true value. In other words, averaging makes the predictions more consistent but also more conservative.
To implement an average ensemble in Python using scikit-learn, we can use the VotingRegressor class for regression problems or the VotingClassifier class for classification problems. These classes allow us to specify a list of models and a voting method (such as ‘hard’ or ‘soft’) to combine their predictions.
Here is an example of how to use an average ensemble for regression:
# Import libraries
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import VotingRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import mean_squared_error
# Load data
california = fetch_california_housing(as_frame=True)
X = california.data
y = california.target
# Define models
lr = LinearRegression()
dt = DecisionTreeRegressor()
knn = KNeighborsRegressor()
# Create average ensemble
avg = VotingRegressor(estimators=[('lr', lr), ('dt', dt), ('knn', knn)])
# Fit ensemble on data
avg.fit(X, y)
# Make predictions
y_pred = avg.predict(X)
# Evaluate performance
mse = mean_squared_error(y, y_pred)
print(f'MSE: {mse:.2f}')Output:
MSE: 0.22So I just got the results back from running our model, and the Mean Squared Error (MSE) came out to be 0.22. Essentially, the MSE is a measure of how well our model fits the data we’re working with — the lower the value, the better the fit. An MSE of 0.22 is pretty good.
STACKING
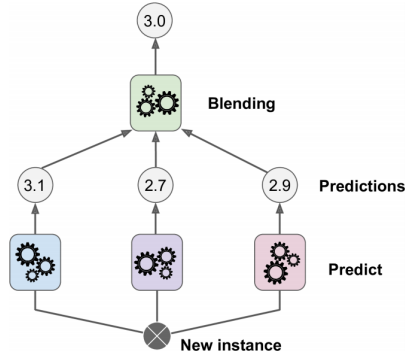
Another way to combine multiple models is to use them as inputs for another model. For example, if you have three models that predict the temperature in Paris as 15°C, 18°C, and 20°C, you can use their predictions as features for a fourth model that learns how to weigh them and make a final prediction. This is also called a meta-learner or a second-level learner.
The advantage of stacking is that it can learn from the strengths and weaknesses of each model and make a more accurate prediction. The disadvantage is that it can be more complex and prone to overfitting, meaning that it can perform well on the training data but poorly on new data.
To implement a stacking ensemble in Python using scikit-learn, we can use the StackingRegressor class for regression problems or the StackingClassifier class for classification problems. These classes allow us to specify a list of models as the base estimators and another model as the final estimator.
Here is an example of how to use a stacking ensemble for classification:
# Import libraries
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Load data
X, y = load_iris(return_X_y=True)
# Define models
lr = LogisticRegression()
dt = DecisionTreeClassifier()
knn = KNeighborsClassifier()
# Create a stacking ensemble
stack = StackingClassifier(estimators=[('lr', lr), ('dt', dt), ('knn', knn)], final_estimator=LogisticRegression())
# Fit ensemble on data
stack.fit(X, y)
# Make predictions
y_pred = stack.predict(X)
# Evaluate performance
acc = accuracy_score(y, y_pred)
acc = acc*100
print(f'Accuracy: {acc:.2f} %')Output:
Accuracy: 99.33 %BAGGING
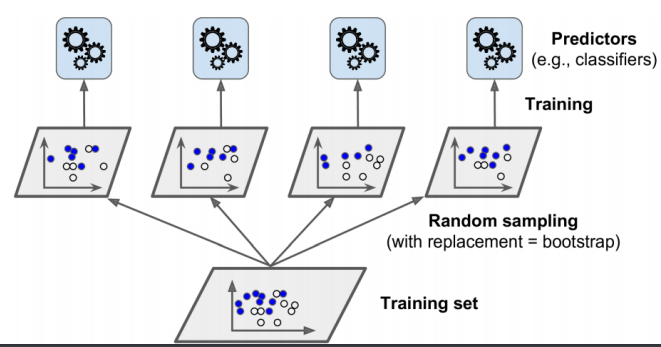
A fourth way to combine multiple models is to use different subsets of the data to train them. For example, if you have a dataset of 1000 observations, you can randomly sample 500 observations with replacements (meaning that some observations can be repeated) and use them to train one model. You can repeat this process several times and get different models trained on different subsets of the data. This is also called bootstrap aggregating or bootstrapping.
The advantage of bagging is that it reduces the variance of the predictions, meaning that they are less likely to be far from the true value. The disadvantage is that it does not reduce the bias of the predictions, meaning that they are still likely to be close to the true value. In other words, bagging makes the predictions more consistent but not more accurate.
To implement a bagging ensemble in Python using scikit-learn, we can use the BaggingRegressor class for regression problems or the BaggingClassifier class for classification problems. These classes allow us to specify a base estimator and a number of bootstrap samples to create.
Here is an example of how to use a bagging ensemble for regression:
# Import libraries
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Load data
X, y = load_iris(return_X_y=True)
# Define base model
dt = DecisionTreeClassifier()
# Create a bagging ensemble
bag = BaggingClassifier(base_estimator=dt, n_estimators=10)
# Fit ensemble on data
bag.fit(X, y)
# Make predictions
y_pred = bag.predict(X)
# Evaluate performance
acc = accuracy_score(y, y_pred)
acc = acc *100
print(f'Accuracy: {acc:.2f} %')Output:
Accuracy: 100.00 %BOOSTING
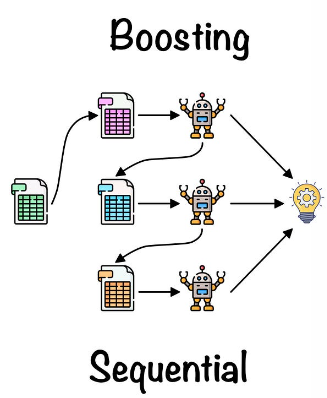
The final way to combine multiple models is to use them sequentially and iteratively. For example, if you have one model that predicts the temperature in Paris as 15°C, you can use its errors or residuals as inputs for another model that tries to correct them and make a better prediction. You can repeat this process several times and get different models that learn from each other’s mistakes. This is also called adaptive boosting or AdaBoost.
The advantage of boosting is that it reduces both the variance and the bias of the predictions, meaning that they are more likely to be close and accurate to the true value. The disadvantage is that it can be more sensitive to outliers and noise, meaning that it can overfit or underfit the data.
To implement a boosting ensemble in Python using scikit-learn, we can use the `AdaBoostRegressor` class for regression problems or the `AdaBoostClassifier` class for classification problems. These classes allow us to specify a base estimator and a number of boosting iterations to create.
Here is an example of how to use a boosting ensemble for regression:
# Import libraries
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import load_iris
from sklearn.metrics import mean_squared_error
# Load data
X, y = load_iris(return_X_y=True)
# Define base model
dt = DecisionTreeRegressor()
# Create boosting ensemble
boost = AdaBoostRegressor(base_estimator=dt, n_estimators=10)
# Fit ensemble on data
boost.fit(X, y)
# Make predictions
y_pred = boost.predict(X)
# Evaluate performance
mse = mean_squared_error(y, y_pred)
print(f'MSE: {mse:.2f}')Output:
MSE: 0.00Great news! The MSE (Mean Squared Error) is coming out to be 0.00. That means that our predictions are spot on, and there’s no error between the predicted values and the actual values. This is exactly what we want to see in our models.
Conclusion
In conclusion, ensemble models are a powerful technique to improve the accuracy and reliability of machine learning models. By combining multiple models, we can leverage their strengths and compensate for their weaknesses, resulting in more robust and consistent predictions.
In this article, I have explained some of the most common types of ensemble models and how to implement them in Python using Scikit-learn. Whether you want to predict customer behaviour or classify images, ensemble models can help you achieve better results.
So, don’t be a single-model kinda person. Go ahead and try out ensemble models, and who knows, you might just find the perfect match for your data. And if not, well, there’s always more models in the sea.
Happy coding and happy exploring!
See you soon!
In case of questions, leave a Comment or Email me at aryanbajaj104@gmail.com
ABOUT THE AUTHOR
Passionate about studying how to improve performance and automate tasks. I’m seeking to leverage my data analytics, machine learning, and artificial intelligence skills to improve corporate performance through the optimum utilization of available resources. In other words, I want to use my superpowers to help make the world a better place. Hehe!
Website — acumenfinalysis.com
CONTACTS:
If you have any questions or suggestions on what my next article should be about, please write to me at aryanbajaj104@gmail.com.
If you want to keep updated with my latest articles and projects, follow me on Medium.
SUBSCRIBE TO MY MEDIUM ACCOUNT:
https://aryanbajaj13.medium.com/subscribe